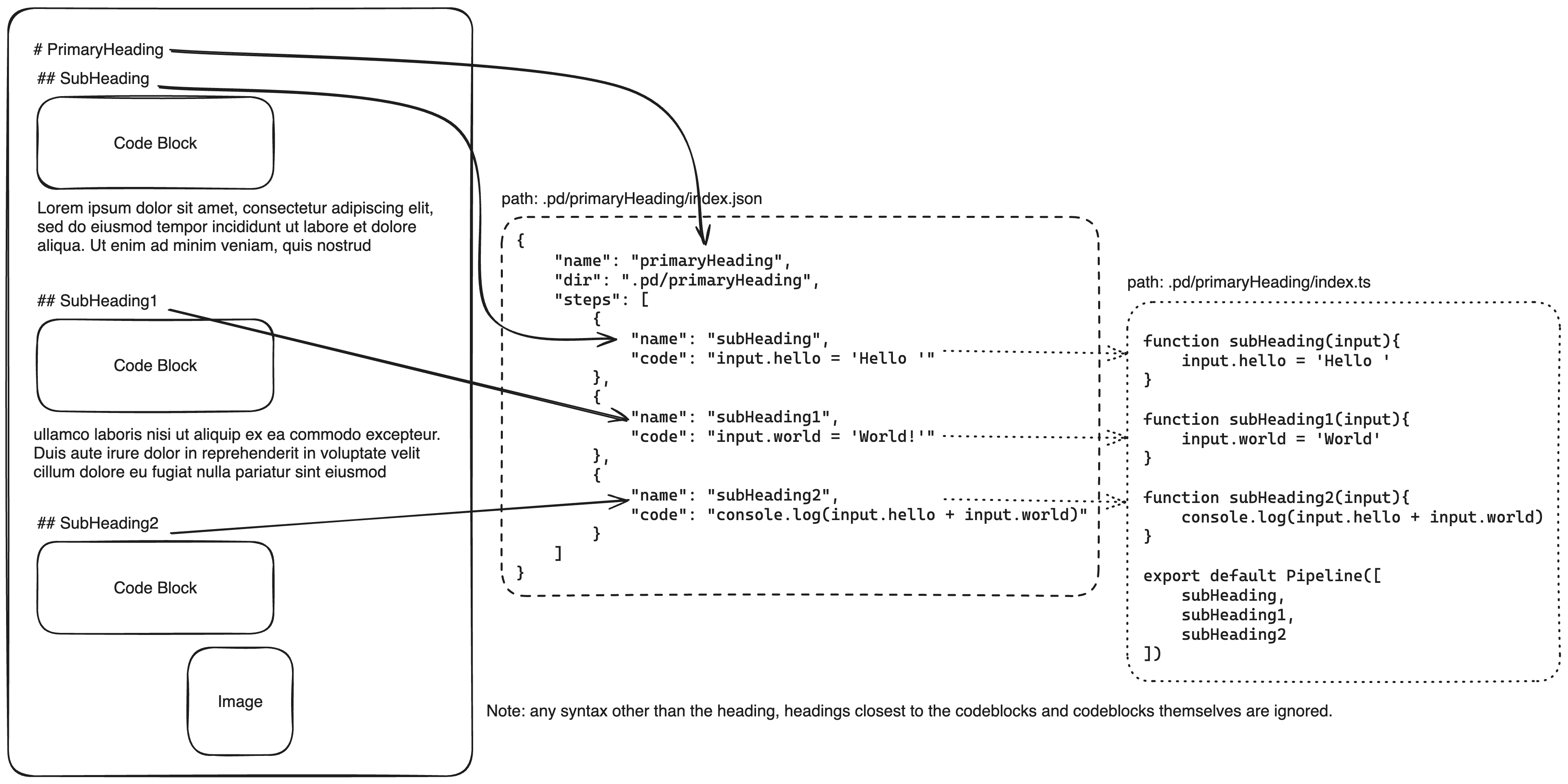
The goal of Pipedown is to extract codeblocks from Markdown and create a "pipeline" of functions. A pipeline will be familiar to anyone who has worked with data. "Piping" data through a sequence of (Extract Transform Load) steps until it is the desired shape.
Each codeblock will become a function, each codeblock will be triggered in the order they are written in the Markdown file. A plain old Javascript object ({}) is passed as an input argument to the first function and passed to each function in turn.
This simple mental model of piping data through a sequence of steps was the inspiration for Pipedown (surprise! 😆). For many years I have looked at web frameworks, command line apps, ETL and low/no-code tools and thought - "they are all the same".
The Pipedown core library is also written as a series of pipelines! Though they are handwritten, they are delightfully readable. Pipedown goes through a few steps to parse Markdown, extract the necessary information and output a Typescript module.